开yun体育网险些占据了总延长的 70-80%-kaiyun·开云(中国)官方网站 入口
2 月 18 日,马斯克发布 Grok 3 的热度还没畴昔,梁文锋就手脚 co-authors 带着 DeepSeek 参谋团队杀了回归。
公布新参谋的推文发布不到 3 个小时,就带来了三十多万的浏览量,火爆进度不逊 OpenAI。

而此次 DeepSeek 团队最新的参谋论文更是重磅,论文中先容了一种全新的,可用于超快速的长陡立文考试与推理的详确力机制 —— NSA,值得一提的是,NSA 还具有与硬件对都的特质,彻底的硬件友好。
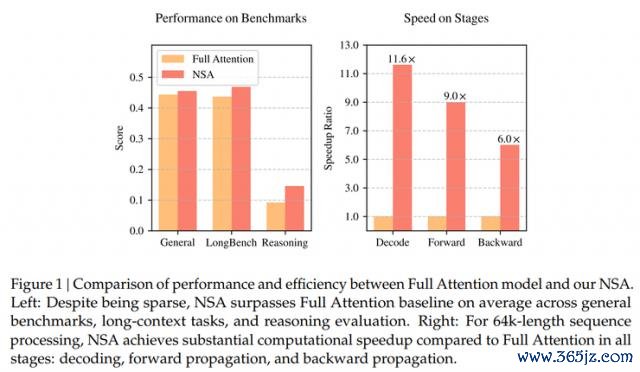
论文中提到的 NSA 中枢构成主要包括三点:辞别是动态分层寥落战略、粗粒度的 token 压缩以及细粒度的 token 遴荐。有了这三点中枢工夫的加捏,就草率在有用裁减预考试资本的情况下,同期显赫耕种推理速率,非常是在解码阶段兑现了高达 11.6 倍的耕种。
更让东谈主感到咫尺一亮的是,DeepSeek 独创东谈主兼 CEO 梁文锋此次也出目前了合驰名单之中,不仅躬行上阵,还躬行提交了论文。

看吵杂不嫌事大的网友以致还借此嘲谑奥特曼:DeepSeek 又发了一篇很强的新论文了哦!
DeepSeek 填补了寥落详确力机制存在的颓势
跟着 AI 范畴的不休发展,长陡立文建模才略的关节性日益突显,尤其在实验寰球的应用中有着平素需求,比如深度推理、代码库级代码生成和多轮自主代理系统。就比如 DeepSeek 自家的 R1 模子即是冲破了这个工夫,使其草率惩办所有这个词代码库、长篇文档,并保捏千千万万 token 的对话连贯性,同期也能在长距离依赖的情境下进行复杂推理。
但序列越来越长,传统的详确力机制就启动因为太过复杂成为了酿成运行延长的最大致素。表面分析走漏,使用 softmax 架构的详确力诡计在解码 64k 长度的陡立文时,险些占据了总延长的 70-80%,传统详确力机制存在较着颓势,耕种速率成了一件相当遑急的事情。
何况当然的兑现高效长陡立文建模的顺序是诳骗 softmax 详确力的固有寥落性,遴荐性地诡计关节的 query-key 对,从而大幅裁减诡计支出,并保捏模子性能。
连年来,干系参谋在这一见解获取了进展,提议了如 KV 缓存淘汰、块状 KV 缓存遴荐,以及基于采样、聚类或哈希的遴荐顺序等战略。尽管这些顺序展示了很大的后劲,但现存的寥落详确力工夫在实质部署时种仍未能达到预期结果。何况大部分参谋主要集聚于推理阶段,枯竭对考试阶段有用撑捏,因此并不成充分阐明寥落方法的上风。
为兑现更高效的寥落详确力,DeepSeek 参谋团队提议了一种原生可考试的寥落详确力架构 NSA,这个架构的中枢内容是通过动态分层寥落战略,结合粗粒度的 token 压缩和细粒度的 token 遴荐,从而保留全局陡立文感知才略和局部精准性。
同期 NSA 通过精妙的算法联想和针对当代硬件的优化,兑目前诡计速率上的显赫耕种,并撑捏端到端考试,既提高了推理效用,又减少了预考试诡计量,同期保捏了模子性能。
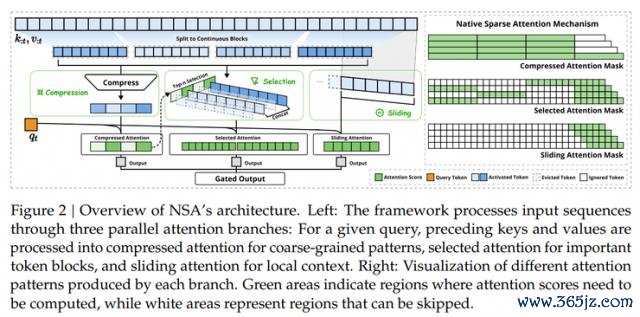
除此除外,新参谋还通过使用 Triton,开拓了与硬件高度兼容的寥落详确力内核。
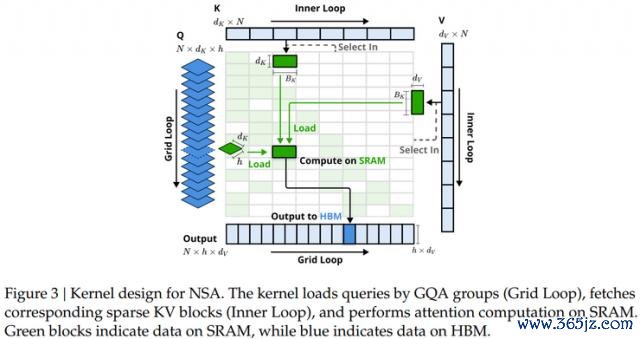
DeepSeek 的优化战略则是给与不同的查询分组顺序,并通过以下性情兑现接近最优的诡计强度均衡:
1、组内数据加载:每次内轮回加载该组所有头的查询独特分享的寥落 KV 块索引。
2、分享 KV 加载:内轮回中联接加载 KV 块,减少内存加载的支出。
3、网格轮反转机:由于内轮回长度在不同查询块间险些同样,将查询 / 输出轮回与 Triton 的网作风仪器结合,简化并优化了内核的推论。
DeepSeek:NSA 已在多面碾压全详确力
在对 NSA 进行工夫评估时,参谋东谈主员辞别从通用基准性能、长文本基准性能、念念维链推感性能三个角度,辞别将 NSA 与全详确力基线和 SOTA 寥落详确力顺序进行比较。
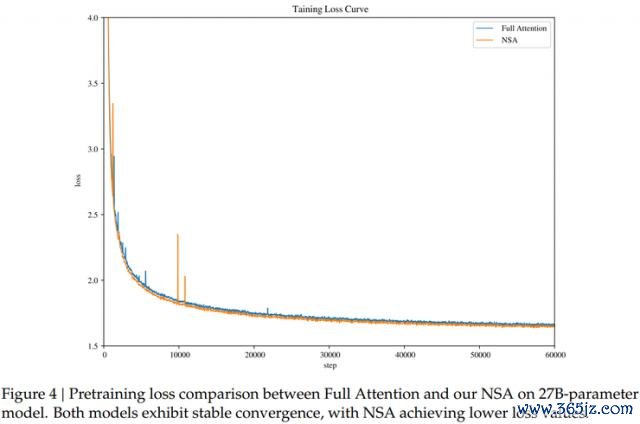
测试中 NSA 的预考试亏蚀弧线比较全详确力基线呈现出愈加健硕和平滑的下跌趋势,且永恒优于全详确力模子。
除此除外,为了考证 NSA 在实质考试和推理中的结果,DeepSeek 参谋团队给与了面前当先的 LLM 常用实践,遴荐了一个结合分组查询详确力(GQA)和混杂行家(MoE)架构的模子手脚样本,该模子的总参数目为 27B,其中 3B 为活跃参数。
在这个基础上,DeepSeek 对 NSA、全详确力和其他详确力机制辞别进行了评估。结果走漏,尽管 NSA 给与了寥落性,但其全体性能仍然优于所有基线模子,包括全详确力模子,何况在 9 项评测策画中有 7 项发达最佳。
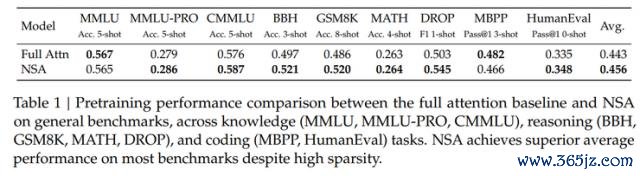
另外,在长陡立文任务中, NSA 在 64k 陡立文的"大海捞针"测试中发达出了极高的检索精度。这归功于其分层寥落详确力联想,通过粗粒度的 token 压缩兑现了高效的全局陡立文扫描,同期通过细粒度的遴荐性象征来保留关节的信息,从而有用均衡了全局感知与局部精准度。
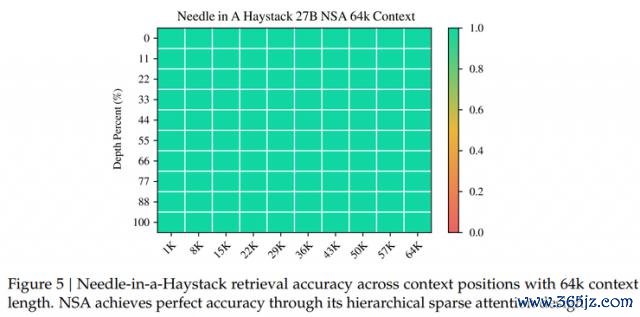
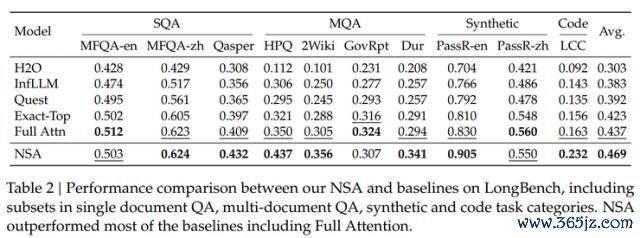
同期参谋团队还在 LongBench 基准上,也对 NSA 进行了评估。最终 NSA 以最高对等分 0.469,优于其他所有基准。
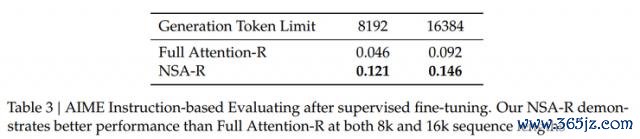
在念念维链推感性能评估方面,参谋东谈主员通过从 DeepSeek-R1 进行常识蒸馏,并借助 100 亿条 32k 长度的数学推理轨迹进行了监督微调(SFT)。
终末用 AIME 24 基准来评估所生成的两个模子 Full Attention-R(全详确力基准模子)和 NSA-R(寥落变体模子)的发达。
在 8k 陡立文建树下,NSA-R 的准确率特出了 Full Attention-R,差距为 0.075。即使在 16k 陡立文环境中,NSA-R 仍然保捏着这一上风,准确率跨越 0.054。
NSA 考证清华姚班早期论文
值得一提的是,论文末尾提到的惩办复杂数学问题的示例,再次考证了两年前清华大学姚班一篇论文中的论断。
由于 Transformer 架构在详确力机制上的局限,惩办复杂数学问题时,tokens 数目过多时常会导致性能下跌,非常是在职务复杂度较高时。
DeepSeek 的最新参谋通过优化问题认知和谜底生成,将所需的 tokens 数目减少至 2275,从而得胜得出了正确谜底。而与之对比的基线顺序,尽管铺张了 9392 个 tokens,最终却得出了造作的谜底。这一显赫的耕种展示了新顺序在效用和准确性上的上风。
清华大学姚班的那篇论文筹商了在 Transformer 架构下,模子在诡计两个四位数乘法(举例 1234 × 5678 )时的发达。参谋发现,GPT-4 在惩办三位数乘法时的准确率为 59%,关联词当任务变为四位数乘法时,准确率却骤降至 4%。这一气候揭示了在面临更复杂诡计时,Transformer 架构的推理才略受到显赫限度。

这些参谋结果标明,尽管 Transformer 架构在某些任务中发达出色,但在惩办复杂推理任务,尤其是需要多半信息惩办时,仍然存在瓶颈。
对于 DeepSeek 论文结果的复杂数学题,雷峰网也用 GPT o3-mini 进行了解读,最终呈现的解题进程比 DeepSeek 论文中给出的解题进程要长出 2 倍之多。
由此可见,大模子的发展即是一个不休吐旧容新的进程。
而反不雅 DeepSeek开yun体育网,将来的参谋可能会愈加专注于怎么优化模子在长文本和代码库分析中的发达,以进一步耕种其推理才略和实用性。




